在之前的文章中我曾写到, 用户和物品的交互关系可以是一个稀疏矩阵, 我们把这个矩阵称作评分矩阵, 比如下面的例子, ? 表示缺失
| user/item | item_0 | item_1 | item_2 | item_3 | item_4 |
|---|---|---|---|---|---|
| user_0 | ? | 2 | 1 | 2 | ? |
| user_1 | 2 | ? | ? | 1 | 2 |
| user_2 | ? | 1 | 1 | 2 | ? |
| user_3 | 1 | ? | ? | 1 | 3 |
| <!— more —> |
所以我们有评分矩阵:
R_\{m,n\} = \\begin\{bmatrix\} ? & 1 & 1 & 2\\\\ 2 & ? & ? & 1 \\\\ ? & 1 & 1 & 2 \\end\{bmatrix\}分解评分矩阵
如果对评分矩阵做低秩矩阵分解(Low Rank Matrix Factorization), 既有, 这就引申到LFM (Latent Factor Model) 隐因子模型,其中隐因子可以理解为一个用户喜欢一个商品的隐形原因,比如电影里面有他喜欢的romantic和action元素,还有他喜欢的某个演员或者导演编剧。如果另外一个电影有类似的元素跟演员,那么他很有可能会也喜欢这部电影。LFM的核心思路就是求出用户矩阵和商品矩阵。
在协同过滤中我们使用item相似度做推荐的核心思想可以用下列公式表达 \begin{equation} \hat{r}{u,i} = \frac{\sum{j \in S^k(i,u)} s_{i,j} r_{u, i}}{ \sum_{j \in S^k(i, u)} s_{i, j}} \end{equation}
其中 代表和物品i最相似的, 并且被用户u交互过k个商品,也就是,如果从LFM的角度考虑, 从评分矩阵求得对应的用户矩阵和商品矩阵, 使得 最小, 那么我们就可以用 来代替评分矩阵从而填充了那些缺失的评分值。
ALS交替最小二乘法
\begin{equation} \min \limits_{p*, q*} \sum\limits_{r_{u, i}\ is\ knwon}(r_{ui} -p_u^Tq_i)^2 + \lambda(||p_u||^2 + ||q_i||^2) \end{equation}
下面就是对上述公式求解使用ALS算法求解矩阵。查阅了一些网上的教程,可以直接化简为一般性的线性回归问题,对于, 的解析解为 , 同理对于, 当固定时, , 当固定时,
但是,我对以上做法持保留意见,在迭代过程中并没有发现RMSE随迭代减小。随后我阅读了原始的文献, 我觉得对于缺失的评分值不应该加入运算,,只会考虑有评分值得情况所对应的线性回归问题。
假设现在有一个稀疏矩阵,以及对应的, ,稀疏矩阵每次按列计算,并且只计算对应值得矩阵, 如公式所示,稀疏矩阵第列只在行和行有值, 那么我们取矩阵的和行,计算线性回归,可以利用正规方程法或者梯度下降法求解,也就是矩阵的第行, 直到求出所有的矩阵的向量。然后再将固定,此时注意维度的统一需要将转置, 求得, 如此循环往复。
\begin{equation}\label{eq3}\begin{split} R &= \begin{array}{cc} & \begin{matrix} 0&1&2&3&4\end{matrix}\ \begin{matrix} 0\ 1 \ 2 \ 3 \end{matrix} & \begin{bmatrix}X& & X & &X \ & X& X& X&\ X& X& & X& \ & & X& X& \end{bmatrix} \end{array}\\ M &= \begin{matrix} & k \ m & \begin{bmatrix} ---\---\---\---\\end{bmatrix} \end{matrix} \\
N &= \begin{matrix} & k \ n & \begin{bmatrix} ---\---\---\---\---\\end{bmatrix} \end{matrix} \end{split}\end{equation}
使用python实现ALS
import numpy as np
import matplotlib.pyplot as plt
def rmse(M, N, R):
a = np.matmul(M, N.T)
idx = list(map(lambda x: (x[0], x[1]), R))
aa = list(map(lambda x:a[x[0]][x[1]], idx))
r = list(map(lambda x: x[2], R))
return np.sqrt(((np.array(aa) - np.array(r))**2).sum()/len(R))
def get_sparse_matrix():
r = [(0, 0, 1), (0, 2, 3), (0, 4, 5),
(1, 1, 1), (1, 2, 1), (1, 3, 1),
(2, 0, 1), (2, 1, 6), (2, 3, 6),
(3, 2, 1), (3, 3, 1)]
return 4, 5, r
def sparse_matrix_transpos(l, r, mat):
m = list(map(lambda x: (x[1], x[0], x[2]), mat))
return r, l, m
def initial(m, n, k):
return np.random.rand(m, k), np.random.rand(n, k)
def als(M, N, l, r, R, lam=0.01):
res =[]
for i in range(r):
mat = list(filter(lambda x: x[1] == i, R))
y = list(map(lambda x: x[2], mat))
idx = list(map(lambda x: x[0], mat))
x = np.array(list(map(lambda x: M[x], idx)))
theta = np.matmul(np.matmul(np.linalg.inv(np.matmul(x.T, x) + lam*np.eye(M.shape[1])), x.T), y)
res.append(theta)
NN = np.array(res)
RR = list(map(lambda x: (x[1], x[0], x[2]), R))
Res = []
for j in range(l):
mat = list(filter(lambda x: x[1] == j, RR))
y = list(map(lambda x: x[2], mat))
idx = list(map(lambda x: x[0], mat))
x = np.array(list(map(lambda x: NN[x], idx)))
theta = np.matmul(np.matmul(np.linalg.inv(np.matmul(x.T, x) + lam * np.eye(NN.shape[1])), x.T), y)
Res.append(theta)
MM = np.array(Res)
return MM, NN
def iterALS(R, iter=10):
it = 0
M, N = initial(4, 5, 2)
rmse_res = []
while(it < iter):
M, N = als(M, N, 4, 5, R) # als(M, N, l, r, R, lam=0.1)
rmse_val = rmse(M, N, R)
rmse_res.append(rmse_val)
print("iter = %d"%it, "RMSE = %f"%rmse_val)
it += 1
plot_acc_loss(rmse_res)
def plot_acc_loss(loss):
plt.figure("rmse")
plt.plot(range(len(loss)), loss, 'r')
plt.show()
if __name__ == '__main__':
m, n, mat = get_sparse_matrix()
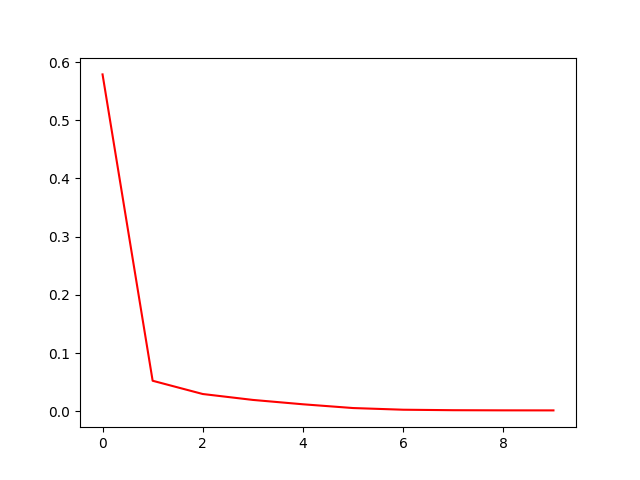
iterALS(mat, iter=10)RMSE如下图:
利用spark计算ALS
鉴于评分矩阵的稀疏性, 我们同样可以借助spark来计算,具体代码如下
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
import breeze.linalg._
import breeze.numerics._
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ArrayBuffer
object Als {
private var spark: SparkSession = _
private var conf: SparkConf = _
private var sc: SparkContext = _
/**
* 随机初始化 M, N
* @param m
* @param n
* @param k
* @return
*/
def initial(m:Int, n:Int, k:Int) ={
val M = sc.parallelize((0 until m ).map(x => (x, DenseVector.rand(k))))
val N = sc.parallelize((0 until n ).map(x => (x, DenseVector.rand(k))))
(M, N)
}
def getRatingMatrix() ={
val mR = sc.parallelize(List((0, 0, 1), (0, 2, 3), (0, 4, 5),
(1, 1, 1), (1, 2, 1), (1, 3, 1),
(2, 0, 1), (2, 1, 6), (2, 3, 6),
(3, 2, 1), (3, 3, 1)).map(x => (x._1, x._2, x._3.toDouble)))
val nR = mR.map(t => (t._2, t._1, t._3))
(mR.cache(), nR.cache())
}
/**
* 计算稀疏矩阵的rmse
* @param M
* @param N
* @param mR
* @return
*/
def rmse(M:RDD[(Int, DenseVector[Double])], N:RDD[(Int, DenseVector[Double])], mR:RDD[(Int, Int, Double)])={
val errRDD = mR.map(x => (x._1, (x._2, x._3))).aggregateByKey(List.empty[(Int, Double)])(_:+_, _++_)
.join(M).map(x => (x._2._1, x._2._2)).flatMap(t => t._1.map(x => (x._1, (t._2, x._2))))
.join(N).map(x => (x._2._1._1, x._2._2, x._2._1._2)) // mVect, nVec, r
sqrt(errRDD.map(x => x._1.t * x._2 - x._3).map( x => pow(x, 2)).sum() / errRDD.count())
}
/**
* 规定维度约束 M * N.t = mR 或者 N * M.t= nR
* @param M
* @param N
* @param mR
* @param nR
*/
def als(M:RDD[(Int, DenseVector[Double])], N:RDD[(Int, DenseVector[Double])],
mR:RDD[(Int, Int, Double)], nR:RDD[(Int, Int, Double)]) ={
val NN = mR.map(x => (x._1, (x._2, x._3))).join(M).map(x => (x._2._1, x._2._2))
.map(x => (x._1._1, (x._2, x._1._2)))
.aggregateByKey(List.empty[(DenseVector[Double], Double)])(_:+_, _++_)
.map{x =>
val matrixX = new DenseMatrix[Double](x._2.length, x._2.head._1.length)
val matX = x._2.foldLeft((matrixX, 0))( (z, t) => { z._1(z._2,:: ):=t._1.t
(z._1, z._2+1)})._1
val vecY = new DenseVector(x._2.map(_._2).toArray)
(x._1, inv(matX.t * matX + 0.01) * matX.t * vecY)
}
val MM = nR.map(x => (x._1, (x._2, x._3))).join(NN).map(x => (x._2._1, x._2._2))
.map(x => (x._1._1, (x._2, x._1._2)))
.aggregateByKey(List.empty[(DenseVector[Double], Double)])(_:+_, _++_)
.map{x =>
val matrixX = new DenseMatrix[Double](x._2.length, x._2.head._1.length)
val matX = x._2.foldLeft((matrixX, 0))( (z, t) => { z._1(z._2,:: ):=t._1.t
(z._1, z._2+1)})._1
val vecY = new DenseVector(x._2.map(_._2).toArray)
(x._1, inv(matX.t * matX + 0.1) * matX.t * vecY)
}
(MM, NN)
}
def iterALS(M:RDD[(Int,DenseVector[Double])], N:RDD[(Int, DenseVector[Double])],
mR:RDD[(Int, Int, Double)], nR:RDD[(Int, Int, Double)], iter:Int = 10)={
val rmse_list =ArrayBuffer.empty[(Int, Double)]
val res = (0 until iter).foldLeft( (M, N, mR, nR))( (z, b) =>{
val res = als(z._1, z._2, z._3, z._4)
val rmseVal = rmse(res._1, res._2, mR)
rmse_list.append((b, rmseVal))
(res._1, res._2, mR, nR)
})
rmse_list.foreach(println)
}
def main(args: Array[String]): Unit = {
val rootLogger = Logger.getRootLogger()
rootLogger.setLevel(Level.ERROR)
conf = new SparkConf().setMaster("local[4]").setAppName("demo")
spark = SparkSession.builder().config(conf)
.config("spark.some.config.option", "some-value")
.config("spark.sql.broadcastTimeout", "20000")
.config("spark.driver.maxResultSize", "25g")
.config("spark.sql.shuffle.partitions", "600")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.shuffle.file.buffer.kb", "10240")
.config("spark.storage.memoryFraction", "0.2")
.config("spark.shuffle.memoryFraction", "0.6")
.config("spark.sql.crossJoin.enabled", "true").getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
sc = spark.sparkContext
val initMatrix = initial(4, 5, 2)
val M = initMatrix._1
val N = initMatrix._2
val R= getRatingMatrix()
val mR = R._1
val nR = R._2
iterALS(M, N, mR, nR)
}
}需要计算的向量会join在一起, 如果两个分解的矩阵不大的话,还可以作为广播变量进一步提高效率。其中的线性回归部分借助breeze包,方法依然是正规方程法。可以替换用梯度下降法。每次迭代的RMSE如下:
(iter:0,rmse = 0.376204)
(iter:1,rmse = 0.126822)
(iter:2,rmse = 0.061821)
(iter:3,rmse = 0.047608)
(iter:4,rmse = 0.042685)
(iter:5,rmse = 0.039862)
(iter:6,rmse = 0.037896)
(iter:7,rmse = 0.036419)
(iter:8,rmse = 0.035267)
(iter:9,rmse = 0.034347)小结
- ALS算法本质上也就是线性回归,但是要注意因为稀疏矩阵的存在导致参与计算的只有部分向量。
- 单机可以处理的情况推荐使用正规方程法,对于更大规模的数据可以使用梯度下降法。